The algorithm was first tested on single-channel speech signals of a single speaker.
A comparison of accuracies between cepstrum and proposed method
for each speaker are shown in table 1.
As the results, our algorithm significantly outperforms cepstrum.
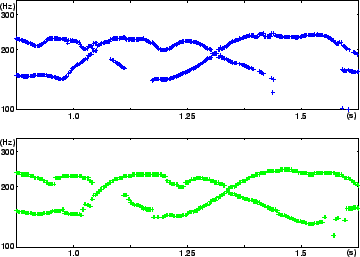
An example of detected ![]() contour is depicted in
figure 3 where the reference is shown in figure 4.
contour is depicted in
figure 3 where the reference is shown in figure 4.
 |
| Speech files | Accuracy(%) | ||
| File 1 | File 2 | Speaker 1 | Speaker 2 |
| `myisda01' | `myisda03' | 63.7 | 63.1 |
| `myisda01' | `myisda04' | 45.7 | 51.6 |
| `myisda02' | `myisda03' | 63.3 | 50.1 |
| `myisda02' | `myisda04' | 59.4 | 42.1 |
| `fymsda01' | `fymsda02' | 57.7 | 54.0 |
| `fymsda01' | `fymsda04' | 53.1 | 41.0 |
| `fymsda02' | `fymsda03' | 52.9 | 59.6 |
| `fymsda02' | `fymsda04' | 64.9 | 64.7 |
| `myisda01' | `fymsda03' | 45.7 | 43.0 |
| `myisda02' | `fymsda05' | 55.0 | 44.5 |
| `myisda03' | `fymsda04' | 41.4 | 59.9 |
| `myisda04' | `fymsda02' | 64.9 | 50.6 |
| `myisda05' | `fymsda03' | 59.4 | 62.8 |
| `myisda04' | `fymsda01' | 62.0 | 71.7 |
| Speech files | Accuracy(%) | ||
| File 1 | File 2 | Speaker 1 | Speaker 2 |
| `myisda01' | `myisda03' | 90.1 | 83.0 |
| `myisda01' | `myisda04' | 92.8 | 81.3 |
| `myisda02' | `myisda03' | 88.2 | 85.7 |
| `myisda02' | `myisda04' | 84.4 | 87.6 |
| `fymsda01' | `fymsda02' | 90.7 | 84.3 |
| `fymsda01' | `fymsda04' | 85.3 | 82.6 |
| `fymsda02' | `fymsda03' | 79.2 | 90.3 |
| `fymsda02' | `fymsda04' | 86.2 | 92.6 |
| `myisda01' | `fymsda03' | 76.1 | 84.9 |
| `myisda02' | `fymsda05' | 74.8 | 92.8 |
| `myisda03' | `fymsda04' | 72.6 | 88.4 |
| `myisda04' | `fymsda02' | 86.3 | 85.5 |
| `myisda05' | `fymsda03' | 78.0 | 86.6 |
| `myisda04' | `fymsda01' | 79.0 | 86.6 |