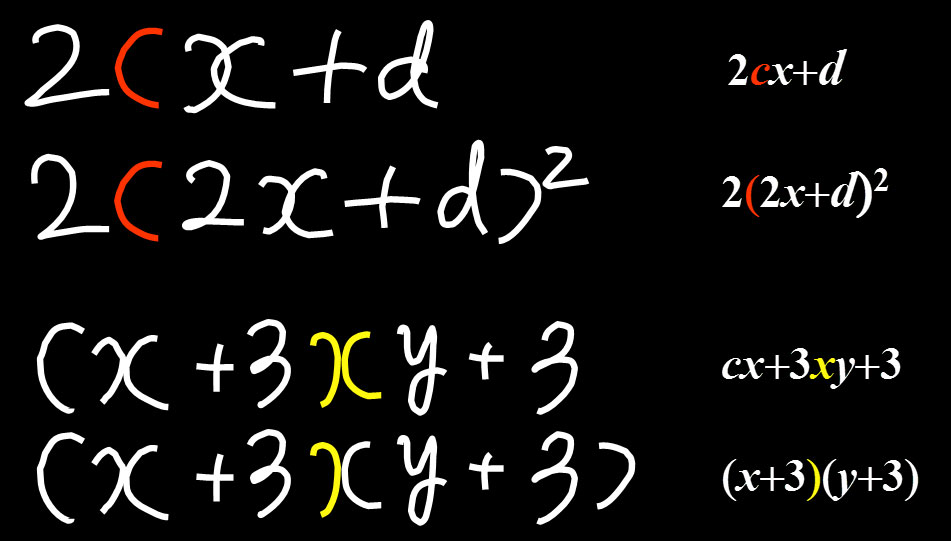

 山本遼 ,
山本遼 ,
 酒向慎司 ,
酒向慎司 ,
 嵯峨山茂樹
嵯峨山茂樹
【動機】「ストローク単位の確率文脈自由文法」によるオンライン手書き数式認識は、確率モデルにより手書き数式をトップダウンにモデル化する新しい枠組みです。オンライン手書き数式認識は、シンボル形状・2次元構造・数式文法などからなる複合問題であり、多くの従来研究はシンボル認識・2次元構造認識・構文解析の3ステップからなるボトムアップな枠組みでこの問題を扱ってきました。しかし数式はシンボル形状が単純でその数も多いことなどから、十分な認識精度を得るには至っていません。
【着眼】図1の例は、数式内シンボルの認識が必ずしもシンボル単独では行えず、周りの文脈、ひいては式全体の構造を考慮する必要があることを示しています。数式のシンボル形状が非常に単純で認識は曖昧にしか行えません。しかし一方で数式には厳格な構文が存在するため、人間はその曖昧性を問題にせず認識できます。ボトムアップな認識の枠組みでは、シンボルを個別に認識した後で全体の構造を解析するため、この重要な問題を本質的に扱うことができません。
それに対しこの手法は、数式の構文をモデル化した文脈自由文法を拡張し、内部に確率的な2次元配置、確率的なストローク形状の生成を含む確率文脈自由文法によりトップダウンに「オンライン手書き数式」の確率的な生成をモデル化します。そして手書き数式認識問題を手書き数式を直接構文解析する問題として、すなわち数式文法の下で2次元配置とストローク形状を同時最適化する数式木構造を求める問題として解きます。
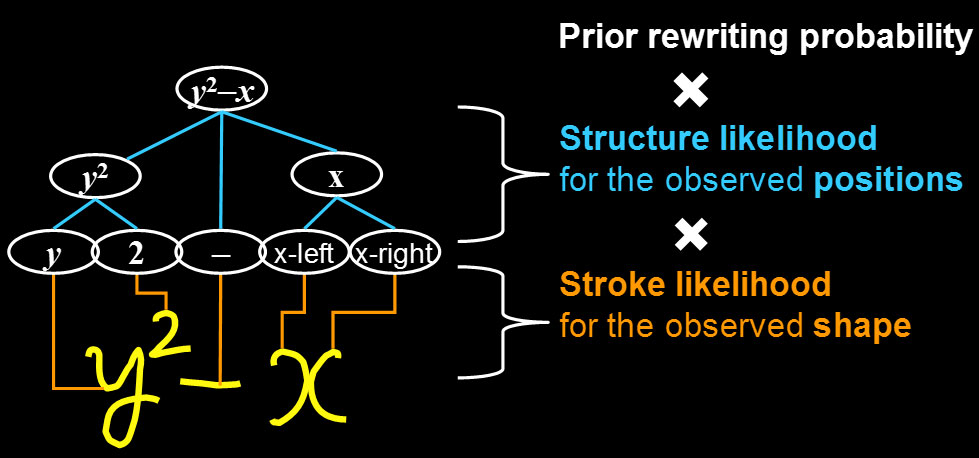
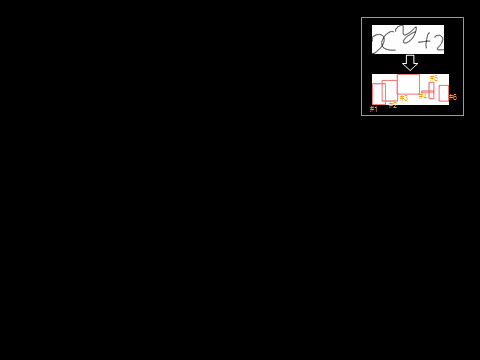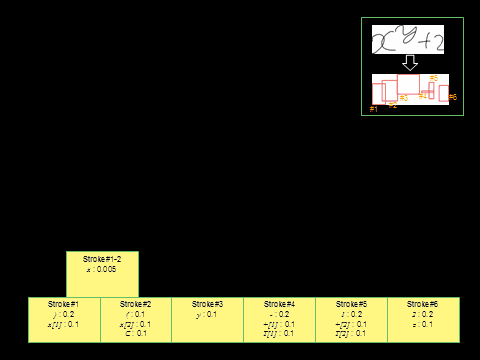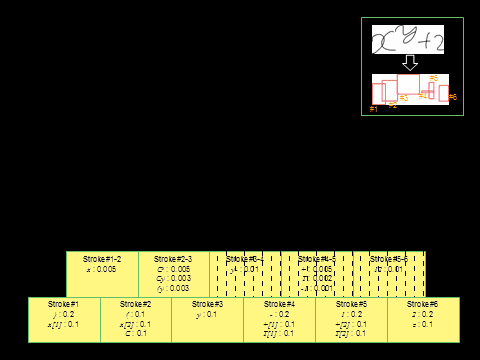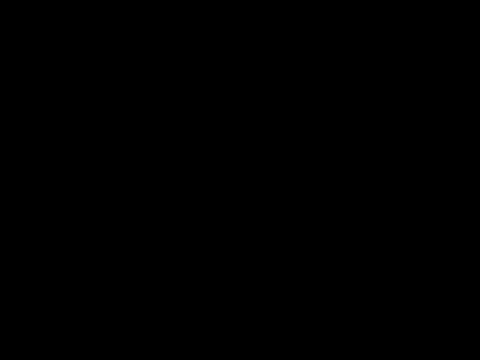
【手法】数式生成をモデル化する確率文脈自由文法は、図2. に示すように数式構文をあらわす文脈自由文法に<右><右上>等の配置演算子を持ち、この演算子に従って非終端記号が確率的に配置されると考えます。またストロークをあらわす"a"、"x-left"などの非終端記号は最終的に規則により形状を持つストロークを生成します。この形状もまた確率的に生成されると考えます。配置の確率モデルとストローク形状の確率モデルにより、手書き数式生成確率が決まります。数式の認識は構文解析問題として、CYKアルゴリズムやLR法などによる最尤解探索により行います。
【特徴】このようにトップダウンな枠組みで構文解析問題として数式認識を行うことにより、この手法は数式の文法を前提としてシンボルや構造を認識する事が可能であり、曖昧なシンボルを文脈情報を利用して認識することにより頑健な認識が期待できます。
|
|
|
|
|
|---|---|---|---|
| 図1. シンボルの認識・分割は必ずしも全体の構文解析なしには行えない。 | 図2. ストローク単位の確率文脈自由文法で記述されたオンライン手書き数式の確率的生成モデル | 図3. 数式認識問題は数式の事前確率、構造尤度、シンボル尤度を最大化する数式仮説の探索問題となる | 図4. CYKアルゴリズムによる認識の手順 |
キーワード: 数式認識, 文字認識, オンライン, 手書き文字, 確率モデル, 確率文脈自由文法, 構造解析
[Yamamoto2005FIT09] にて初めてこの手法と予備的な実験結果を発表しました。実験結果と定式化を加えたものとして [Yamamoto2006PRMU02] を、さらに生成モデルとしての視点から定式化に整理を加えたものとして [Yamamoto2006IWFHR10] を発表しました。また学習・評価用に行った数式データベース作成について [Yamamoto207PRMU03] にて、この手法を手書き漢字認識に応用した研究について [Ota2007PRMU03] にて発表しています。
 |
 |
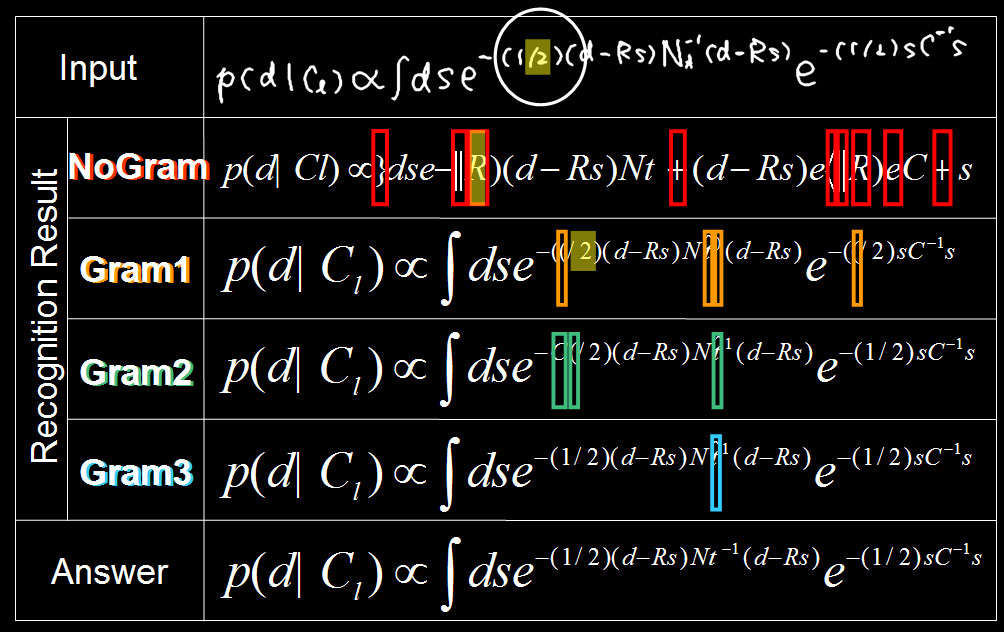 |
|---|---|---|
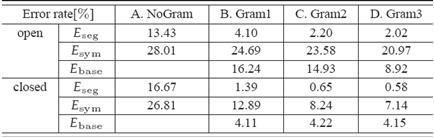
| 図5. 評価データセットの手書き数式例。 | 図6. シンボル分割誤り率(Eseg)、シンボル認識誤り率(Esym)、シンボルのベースライン推定誤り率(Ebase)を表に示します。文法制約が強くなるにしたがって誤りが減少することが確認できます。本手法により文脈情報を利用して頑健性を増すことができるということが確かめられます。 | 図7. この認識例を見ても四角で囲ったシンボル誤りが文法制約を強めるに従って減少することが確認できます。 |
関連内容として、 [Yamamoto2006IWFHR10] の解説記事や各論文のPDFファイルもご覧ください。