Technical
Introduction
On-Line Recognition of Handwritten Mathematical Expressions
Based on Stroke-Based Stochastic Context-Free Grammar
Ryo Yamamoto, Shinji Sako, Takuya Nishimoto, Shigeki
Sagayama
Sagayama / Ono Lab., The
1. Introduction
The problem of
On-line handwritten
mathematical expression recognition is to convert a Tablet input mathematical
expression into
Intensive research has
already been conducted on this problem, and most of the existing systems take
bottom-up, hierarchical approaches. First they segment and recognize symbols of
the input stroke sequence and secondly recognize the 2D structure between
symbols. Finally, they syntactically analyze the estimated symbols and
structure so that the result is grammatically right. But this hierarchical
recognition intrinsically faces error correction problems. The system makes
hard decisions in each layer, so it cannot correct errors made in lower layers
using information in higher layers. To cover this problem, some methods
such as simultaneous symbol segmentation and recognition (KosmalaˇÇ98),
rejection-based alternative exploration (GarainˇÇ04), and the use of
fuzzy logic (FitzgeraldˇÇ06) have been proposed.
For example, the red
stroke in each of the expression below has the same shape. But in the first
expression, the stroke is 'c', and in the second 'left parenthesis'. This example
shows that symbols cannot be determined prior to ME analysis.
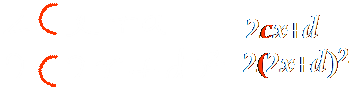
In the next example below, the
yellow strokes in the first ME should be recognized as 'x', while the
yellow stroke in the second should be 'right parenthesis'. This example
shows that we cannot even
segment symbols prior to the whole ME analysis.
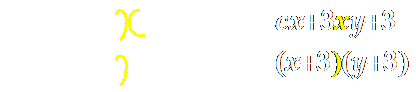
So we need to determine
segmentation, symbols, and structure simultaneously considering the grammar.
In the light of this,
we aim to build a new Unified Top-Down Framework, instead of Hierarchical,
Bottom-Up ones, to this problem. We propose a stochastic generation model of
handwritten ME, and we perform recognition with MAP estimation. This
method is free
from any hard decision process, and thus is free from the error correction
problems. Moreover, this modeling will also give a clear viewpoint to
existing fuzzy approaches.
2. Proposed Framework
We modeled the
generation of handwritten ME with a mathematical grammar written in the form of
Context-Free grammar, such as the ones used in C or matlab
languages. But there are two differences. First the generation rule includes
a PLACEMENT OPERATOR to represent the placement of the nonterminal symbols
like "right" or "upperright", marked in BLUE. Second, the terminal
symbols are
the shape of the strokes themselves, not a string.
Let me show you an
example of generation. First, the expression non-terminal symbol is placed at a
certain position.
The generation rule #1
is applied and expression, operator, expression, non-terminal symbols are
generated, with probability equal to the rewriting probability of the rule. At
the same time, the
positioning of these non-terminal symbols is stochastically determined
according to the placement operators, with probability equal to the positioning probability.

Next, the rule #1
changes the expression to term, also with its rewriting probability. #2, term
to factor, #3, factor to power, the powered variable. Rule #4 generates
variable and expression with probability equal to the rewriting probability, and the positioning is
stochastically determined. The variable turns into y. Rules are applied in the
same way.
Note that this model
generates STROKES, not SYMBOLS, because the input of Handwritten ME, which we
should model, is just a Stroke Sequence, not segmented to form symbols. So for
multi-stroke symbols, we introduced stroke generation rules like rule #8. The X
generates x-left, and x-right, and the position is stochastically decided.
Finally, the terminal
symbols, the shape of the strokes, are generated with rule #9 to 13
stochastically with their Stroke Shape probability of the strokes. In this way,
this model generates stochastically the handwritten ME "y powered by 2 minus x".
So far, we modeled the
stochastic generation process of positions and shapes of handwritten strokes,
and the model is in the form of a Stroke-Based Stochastic CFG. The Rules are
extended with placement operators, the non-terminal symbols are associated with
positions, and the terminal symbols are the handwritten stroke shapes. The
grammar has 3 types of probability: Rewriting, Positioning, and Stroke shape
probability.
With this generation
model, the recognition problem is to find the Maximum a
posteriori derivation tree. In other words, to directly parse the observed
handwriting. The 3 probabilities in the model here turn into Prior rewriting
probability, Structure likelihood, and Stroke Likelihood for the observation.
We should model these probability and likelihoods. We also have to use some
search algorithm to find the MAP tree.
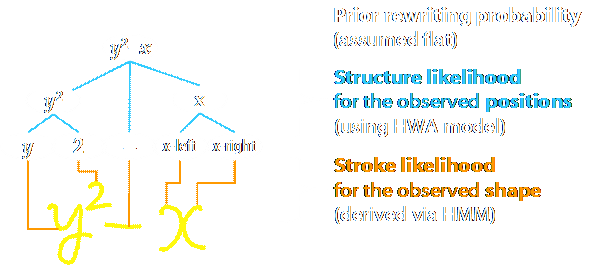
Here, we assumed the prior rewriting
probability flat, so we in fact performed the maximum likelihood
recognition. We modeled the
structure likelihood using the Hidden Writing Area (HWA) model that we
introduced.
We derived the stroke likelihood via HMMs, and used the CYK search algorithm.
3. Stroke and Structure Models
HMM stroke models are
simple 10-state left-to-right models. We used x, y, delta-X, delta-Y as the
feature vector.
We modeled the
positioning of the strokes with the Hidden Writing Area (HWA) model. This
model is rather intricated and we shall only explain it very briefly here.
HWA is a Top-Down
generation model of stroke positioning. We assume that when we write a ME, we
have an imaginary box area to write the ME in our mind, as shown
below. And this
imaginary box, which we call Hidden Writing Area (HWA), generates the HWAs for
the sub-expressions successively,
stochastically according to the grammatical structure of the ME as shown
in the
following figure.
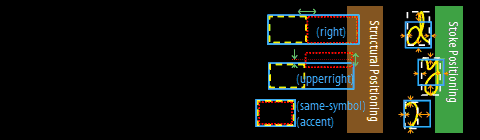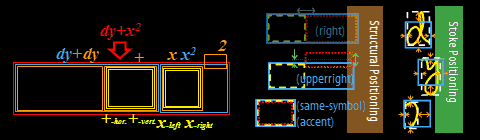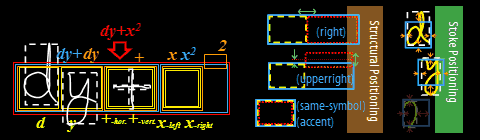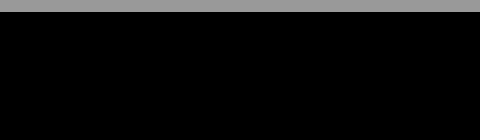
Finally, the HWA for each
stroke is stochastically determined, and the Bounding box of the stroke
is stochastically
placed on the corresponding HWA. The placement tendency is modeled for each
stroke, e.g., the stroke 'd' tends to be placed upperward against the HWA, 'y' downward,
x-left, leftward. The tendency parameters of Structural positioning and Stroke
Positioning are stochastically trained with the EM algorithm. Using this model, we
can avoid the bottom-up bounding box problems.
4. Search Algorithm
We used the CYK search
algorithm to find the ML tree. First we list the stroke candidates for each
stroke with its stroke likelihood. We then combine the candidates in a
bottom-up
way, multiplying by the structure likelihood. The recognition result comes at the top
of the matrix.
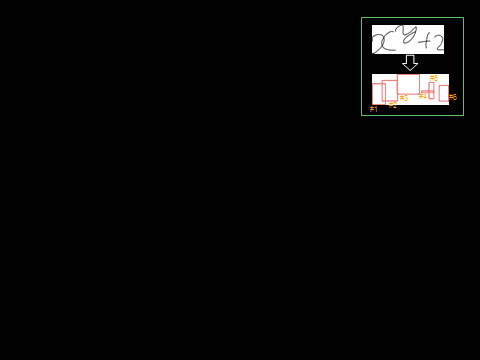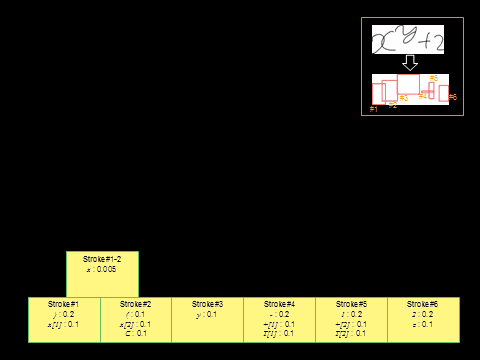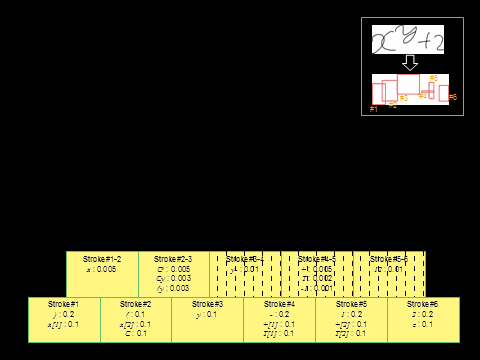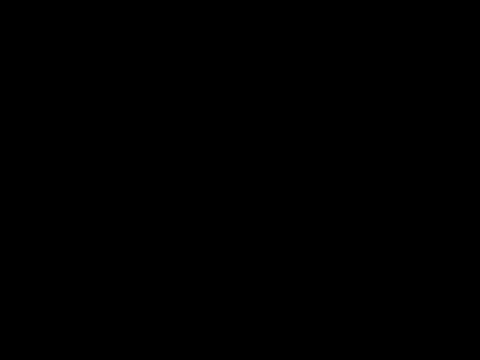
4. Experiments
We conducted experiments
to validate this framework. Here we compared 4 grammar
conditions: NOGRAM, Gram1, Gram2, and Gram3. In the NOGRAM condition, Structure
likelihood among symbols is flat. This means that
this condition assumes symbols to be randomly placed. So this condition can
emulate the baseline symbol-only recognition. The GRAM1 is a simple grammar as
The evaluation set
consists of 8 MEs from IEEE articles, each written 10 times by 1
writer. For HWA training, the training set consists in
7 MEs written 40 times by the same writer. 5 MEs are common to the evaluation
set. For the training of the positional tendency for each
stroke, we require every symbol in the target domain to appear in the
expression training data, not isolated character data. Because it is
difficult to design a training set to cover all the symbol domain of the
evaluation set, we shared some MEs. So the symbol domain is rather
small, with 52
symbols here. Basic mathematical 2D structures like sub/super-script, fraction,
root, upper-lower-script, accent are modeled.
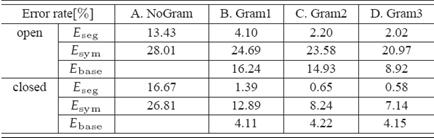
The segmentation error,
symbol recognition error, and baseline error rates are shown here. Although the
symbol recognition rate is not very good, because of the very basic
modeling with HMM, we can see that all error rates decrease along with the
strengthening of the grammatical constraint. Considering that Gram1 has
such a small constraint that it permits every symbol sequence, we can
see by comparing
NoGram to
Gram1 that symbol errors decreased thanks to the symbol-structure
simultaneous estimation.
Let me show you some examples. The
square marks are the stroke recognition error, which decreased along with the
grammatical constraint strengthening. Now please look at the strokes
marked in yellow.
These strokes are "one slash 2", but in symbol-only recognition, it was
mis-recognized as 'R'. Using structure and grammar simultaneously, we could
correctly recognize these strokes. This is the very example of what we wanted
to do at first.
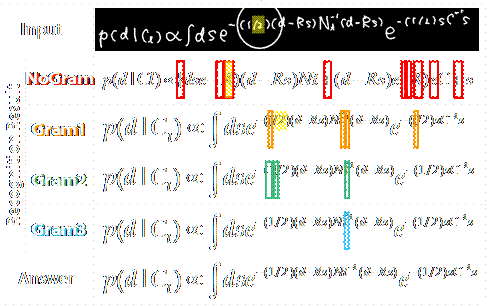
6. Conclusion
In conclusion, aiming
at a unified framework for handwritten ME recognition, we
proposed a Stroke-Based Stochastic CFG generation model. It consists in
a ME grammar with
placement operator, where Non-terminal symbols are associated positions, and Terminal
Symbols are the stroke shape. We perform recognition of the input with
MAP estimation. Here, we assumed that the rewriting probability was
flat, used HMM for
Stroke Shape probability, HWA for Positioning probability and CYK as the Search
algorithm. We confirmed that symbol segmentation and recognition error
decreases by performing simultaneously structure estimation and
grammatical analysis.
Our future works
include evaluation on larger databases, design of an optimal ME grammar,
modeling rewriting probability, and application of faster search algorithms.