Joint approach to acoustic scene analysis
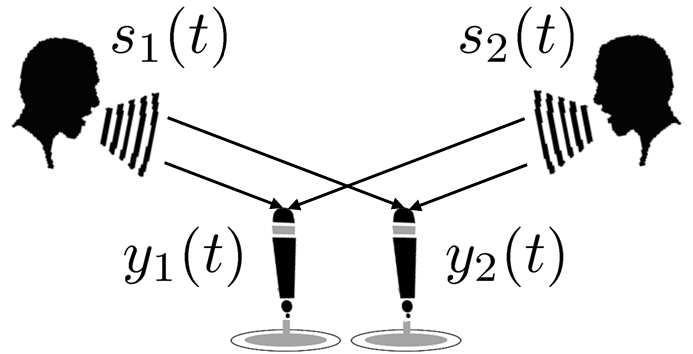
Humans are able to recognize what kinds of sounds are present and which direction they are emanating from by using their ears. The goal of acoustic scene analysis is to develop a method that let machines imitate this kind of human auditory function. The problems of source separation, audio event detection, source localization, and dereverberation have long been important subjects of interest by many researchers in the world. Since each of these problems is ill-posed, some assumptions are usually required. For example, many methods for source separation assume anechoic environments, many methods for audio event detection assume that no more than one audio event can occur at a time, and many methods for source localization and dereverberation assume that only one source is present. All these algorithms work well when certain assumed conditions are met but, nevertheless, have their limitations when applied to general cases. By focusing on the fact that the solution to one of these problems can help solve the other problems, we have proposed a unified approach for solving these problems through a joint optimization problem formulation.
Generative modeling of voice fundamental frequency contours
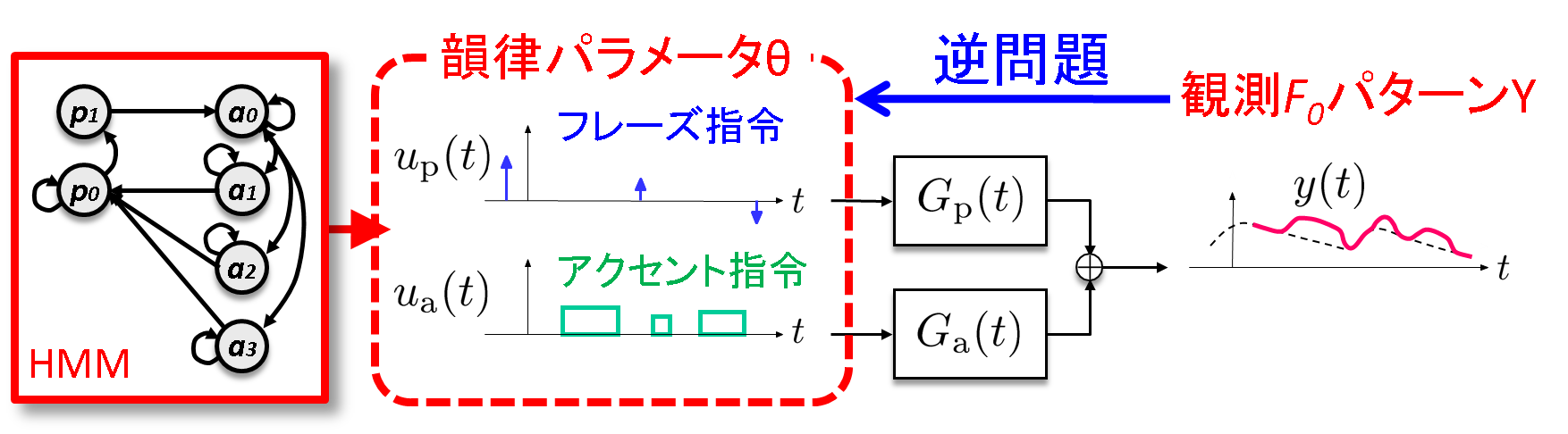
Linear Predictive Coding (LPC), proposed in the 1960s, has established the modern speech analysis/synthesis framework and has opened the door to the mobile phone technology and the research paradigm of statistical-model-based speech information processing. While LPC has realized the analysis/synthesis framework focusing on the 'phonemic' factor of speech, we have developed a new analysis/synthesis framework focusing on the 'prosodic' factor. Although a well-founded physical model for vocal fold vibration was proposed in the 1960s by Fujisaki (known as the "Fujisaki model"), how to estimate the underlying parameters has long been a difficult task. We have developed a stochastic counterpart of the Fujisaki model using a discrete-time stochastic process, which has made it possible to apply powerful statistical inference techniques to accurately estimate the underlying parameters. Another important contribution of this work is that it has provided an automatically trainable version of the Fujisaki model, which allows it to be developed into a new module for Text-to-Speech, speech analysis, synthesis and conversion systems.
Optimization with auxiliary function approach
For many nonlinear optimization problems, parameter estimation algorithms constructed using auxiliary functions have proven to be very effective. The general principle is called the "auxiliary function approach". It should be noted that this concept is adopted in many existing algorithms (For example, the expectation-maximization (EM) algorithm can be seen as a special case of this approach). In general, if we can build a tight auxiliary function for the objective function of a certain optimization problem, we expect to obtain a well-behaved and fast-converging algorithm. In fact, we have thus far proposed deriving parameter estimation algorithms based on this approach for various optimization problems, some of which have been proven to be significantly faster than gradient-based methods. Motivated by these experiences, we are concerned with using this approach to develop algorithms for solving many optimization and machine learning problems, including training restricted Boltzmann machines and deep neural networks.
Stochastic and psycho-acoustical approach to music transcription
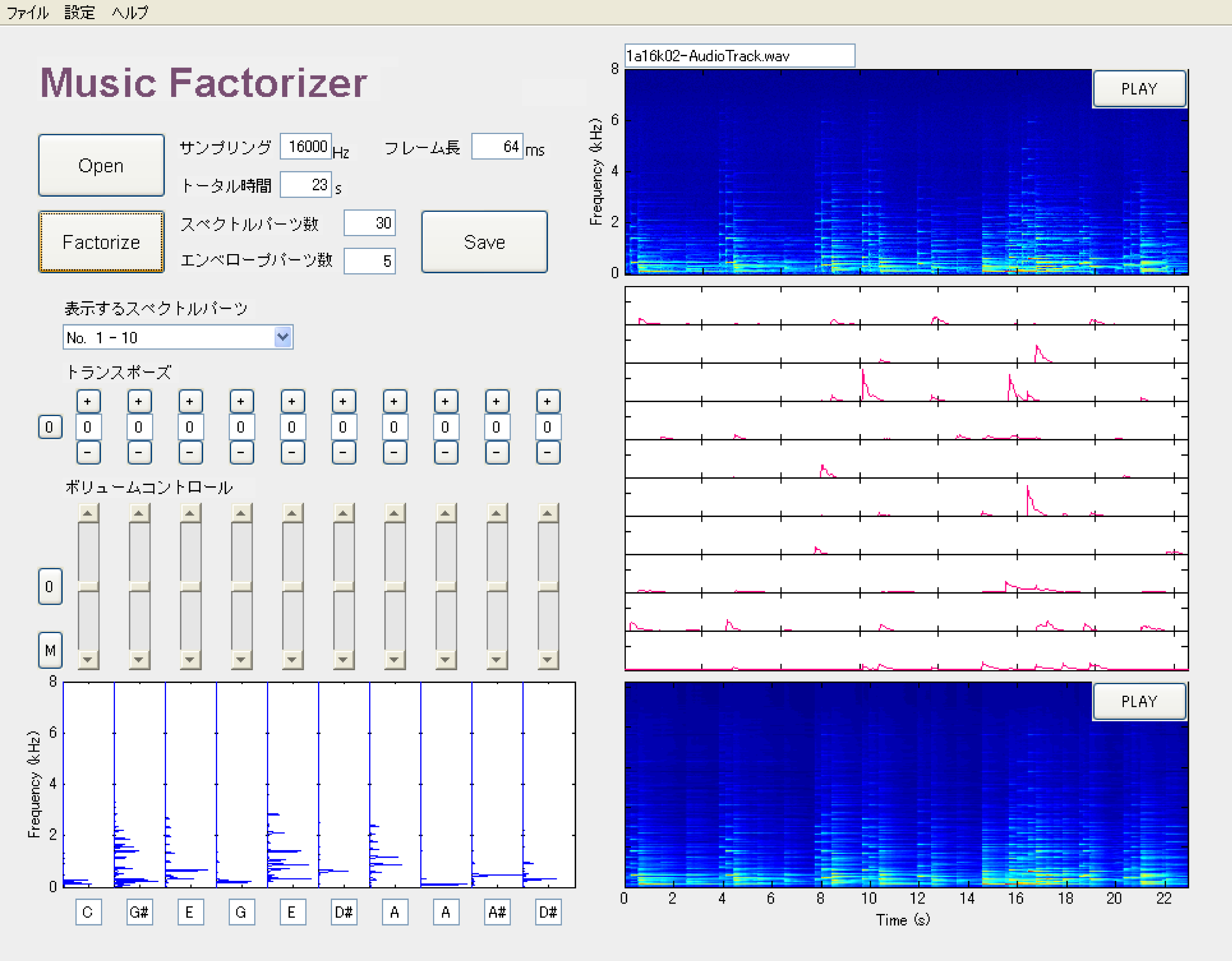
Humans are able to pay attention to a single melody line in polyphonic music. This ability is called the auditory stream segregation, which consists in grouping time-frequency elements into a perceptual unit called the auditory stream. We have proposed a novel computational algorithm imitating this auditory function by formulating the time-frequency structure of an auditory stream.
Similarly to speech recognition, that has a significant potential in many directions, music transcription is an important and challenging research topic. However, the performance of state-of-the-art techniques is still far from sufficient. A key to its solution is to build a top-down system, similar to speech recognition systems, that can hypothetically extract simultaneous notes and evaluate whether those extracted notes follow a musically likely score structure. We have proposed a new approach to music transcription based on a top-down system combining the abovementioned psycho-acoustically-motivated model with a language model for the musical score structure described by a 2 dimensional extension of the probabilistic context free grammar (PCFG).