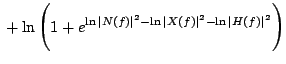An acoustical model demonstrating the effect of additive noise ![]() and channel filtering
and channel filtering ![]() over a clean speech signal
over a clean speech signal ![]() is shown in Figure 1.
is shown in Figure 1.
The corrupted speech is given by:
Thus, the relationship between speech and noise is non-linear one, as given in Eq.(4). Experiments show that even if noise and clean speech parameters have Gaussian distribution (in log-domain), the corrupted speech parameters do not have Gaussian distribution anymore. However, if parameters have low variances, and in case a number of mixtures of Gaussians are used to model their distributions, the distribution of parameters can be still assumed to be Gaussian without much loss of accuracy; and the same decoder optimized for Gaussian distribution can be used.