東京大学大学院情報理工学系研究科システム情報学第一(嵯峨山・小野)研究室
研究内容解説 (最終更新: 2007.03.21)
音楽演奏の確率モデルに基づく自動採譜
 武田 晴登 ,
武田 晴登 ,
 西本卓也 ,
西本卓也 ,
 嵯峨山茂樹
嵯峨山茂樹
音楽演奏の確率的生成モデル
【動機】 人間の表情豊かな演奏を計算機に理解させる---それは音楽制作のための実用上の要請であるだけでなく、多くの音楽研究者達の大きな目標のひとつです。しかしこの人間の豊かな表情・個性は機械にとっては単純な演奏を複雑にしてしまう変動であり、例えば音楽演奏MIDI情報を自動認識し楽譜化するという一見単純な問題も、その解決は非常に困難です。
【着眼】
音楽演奏中の個々の音をいくら解析しても、その音がどんな音符であるかを正確に知ることはできません。しかしひとつながりの演奏を聴くと、私たちは各音がどんな音符で楽譜上のどの位置にあるかが自然とわかります。このことは音声信号の各フレームからはその瞬間の音素を推定することができないにもかかわらず、全体の音声を聞けば各瞬間の音素もまたはっきり理解されるという、音声認識問題の興味深い側面と一致しています。
【音声認識との類似性】
音声認識の技術は、この問題を隠れマルコフモデル(HMM)というトップダウンな枠組みで解析することにより扱うことに成功しました。この枠組みは音声信号を、1.単語が並ぶことで発話内容が確率的に生成され、そこから音素の並びが生成される、2.各音素からフレームごとの音響信号の系列が確率的に生成される、という生成モデルの出力ととらえ、逆問題を解くことで発話を推定します。これは「入力音響信号が意味のある単語の系列である」という前提の元でその単語列を推定することに相当し、人間が「言葉だと思って(先入観を持って)」話を聞くことの模倣といえます。
私たちは音楽の演奏を聴くときも、このように「音楽だという前提で」聴いています。典型的な音楽には拍子があり、それがめまぐるしく変化したりはしません。したがって人は多くの場合、典型的なリズムに当てはめようとしながら演奏を聴きます。私たちは音楽演奏を音声認識のモデル化にならい、1.いろいろなリズムパターンの小節が確率的に並び、そこから音符列が生成される、2.各音符から実際の演奏音が確率的に生成される、というモデルを立てて逆問題として楽譜を推定することにより、演奏のより人間の直感に近い解釈を可能にしました。
【手法】
音声認識における「単語」を、いろいろなリズムパターンの小節=「リズム語彙」に、「音素」を「音符」に、「音響特徴」を「発音時刻間隔」に対応させ、音声認識で用いられるHMMによりモデル化を行います。自動採譜は音声認識と同じViterbi探索により高速に行うことができます。また演奏の大局的なテンポ変動のモデルも加えることで、ダイナミックな演奏にも追従可能です。
【特徴】 リズム語彙を用いたHMMにより、典型的な音楽とは何かといった事前知識を用いた音楽の認識が可能となり、頑健性が期待できます。またテンポ曲線の導入により演奏中の曲調の変化にも柔軟に追従できる期待があります。
 |
 |
 |
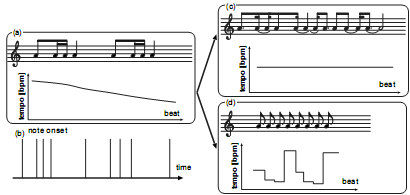
| 図1. 意図したテンポ変動(a)と、誤ったリズム解釈による誤ったテンポ変動の認識(c,d)
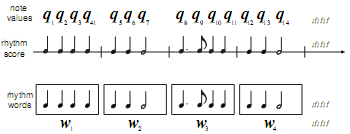
| 図2. リズム譜のリズム単語によるモデル化
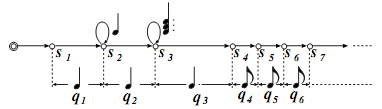
| 図3. 拍位置のマルコフ遷移リズム譜のモデル化
|
キーワード: リズム認識, 隠れマルコフモデル, テンポ解析, 連続音声認識
関連文献
- 論文誌
- 大槻 知史, 齋藤 直樹, 中井 満, 下平 博, 嵯峨山 茂樹, ``隠れマルコフモデルによる音楽リズムの認識,'' 情報処理学会論文誌,
vol.43, no.2, pp.245-255, Feb, 2002.
- 武田 晴登, 篠田 浩一, 嵯峨山 茂樹,
“確率モデルによる多声音楽演奏のMIDI信号のリズム認識,” 情報処理学会論文誌, vol.45, No.3, pp.670-679, Mar,
2004.
- 武田 晴登, 西本 卓也, 嵯峨山 茂樹, “テンポ曲線と隠れマルコフモデルを用いた多声音楽MIDI演奏のリズムとテンポの同時推定,”
情報処理学会論文誌, Vol. 48, No. 1, pp.237-247, Jan, 2007.
- 国際会議(査読有り)
- Haruto Takeda, Naoki SAITO, Tomoshi OTSUKI, Mitsuru NAKAI, Hiroshi
SHIMODAIRA, Shigeki Sagayama, ``Hidden Markov Model for Automatic
Transcription of MIDI Signals,'' In Proceedings of IEEE
Workshop on Multimedia Signal Processing,
December, 2002.
- Haruto TAKEDA, Takuya NISHIMOTO, Shigeki SAGAYAMA, "Automatic
Transcription of multiphonic MIDI Signals," in Proceedings of
4 th International Conference of Music
Information Retrieval(ISMIR), October 26-30, pp. 263--264, 2003.
- Haruto TAKEDA, Takuya NISHIMOTO, Shigeki SAGAYAMA, "Maximum Likelihood
Method for Estimating Rhythm and Tempo," in Proceedings of
International Symposium of
Musical Acoustics (ISMA) 2004, March, 2004.
- Haruto TAKEDA, Takuya Nishimoto, Shigeki Sagayama, ``Rhythm and Tempo
Recognition of Music Performance from a Probabilistic Approach," in
Proceedings of 5th International Conference on Music Information Retrieval
(ISMIR), October 10-14, pp. 357-364, 2004.
- 国内大会
- 武田 晴登, 篠田 浩一, 嵯峨山 茂樹, ``リズムベクトルを用いたHMMによる 単旋律MIDI演奏の楽譜化,''
日本音響学会2002年秋季研究発表会講演論文集, 1-1-5, Sep 2002.
- 武田晴登,西本卓也, 篠田浩一,嵯峨山 茂樹, ``HMMを用いた多声部 MIDI信号からの楽譜復元,''
日本音響学会2003年春季研究会講演論文集 3-7-3, pp. 837--838, 2003.
- 武田 晴登,西本卓也, 嵯峨山 茂樹, ``確率モデルによるMIDI演奏のテンポ 変化時点の検出,''
日本音響学会2003年秋季研究発表会講演論文集.
- 嵯峨山茂樹, 武田晴登,亀岡弘和,西本卓也: ``音楽情報処理と音声認識,'' (招待講演), 日本音響学会2004年春季研究発表会講演論文集, 2-6-9,pp.785-788, Sep. 2004.
- 武田 晴登, 西本 卓也, 嵯峨山 茂樹, ``HMMを用いたリズムとテンポの反復推定による多声MIDI演奏のリズム認識,''
日本音響学会2006年春季研究発表会 講演論文集, 3-2-3, pp.721-722, Mar, 2006.
- 武田 晴登, 西本 卓也, 嵯峨山 茂樹,``和音の発音順序交替を許容した動的計画法による多声音楽音MIDI演奏の楽譜追跡,''
日本音響学会2006年春季研究発表会 講演論文集, 3-2-4, pp.723-724, Mar, 2006.
- 宮本 賢一,亀岡 弘和,武田 晴登, 西本 卓也, 嵯峨山 茂樹,``HTC多
重音ピッチ推定とHMMリズム・テンポ推定を統合した音響信号からの自
動採譜の検討,'' 日本音響学会2006年秋季研究発表会 講演論文集, 2006.
- 山本 遼,武田 晴登, 酒向 慎司, 嵯峨山 茂樹,``確率文脈自由文法を
用いた音楽演奏MIDIデータのリズム・テンポ推定,'' 日本音響学会2006年秋季研究発表会 講演論文集, 2006.
2006.
- 研究会
- 武田晴登, 篠田浩一, 嵯峨山茂樹, ``リズムベクトルの概念に基づくMIDI演奏の音価認識,'' 情報処理学会音楽情報科学研究会 研究報告
2002-MUS-46-4, pp.23-28, Jul 2002.
- 武田晴登, 西本卓也, 篠田浩一, 嵯峨山茂樹, ``確率モデルによる多声楽曲MIDI演奏からの楽譜推定,'' 情報処理学会 音楽情報科学研究会
研究報告 2003-MUS-50-4, pp. ?-?, May 2003.
- 武田晴登, 西本卓也, 嵯峨山茂樹, ``リズムベクトルを用いたMIDI演奏 データからのテンポの変動の推定,'' 情報処理学会
音楽情報科学研究会 研究報告2003-MUS-51, pp. 59-64, Aug 2003.
- 武田晴登, 西本卓也, 嵯峨山茂樹, "リズム語彙を用いたHMMによるMIDI演
奏のリズムとテンポ推定,"情報処理学会音楽情報科学研究会研究報告
2004-MUS-54, Mar, 2004.
- 武田晴登, 西本卓也, 嵯峨山茂樹,
"HMMによるMIDI演奏の楽譜追跡と自動伴奏,"
情報処理学会研究報告(MUS), pp.109-116, Aug, 2006.
自動採譜実験結果
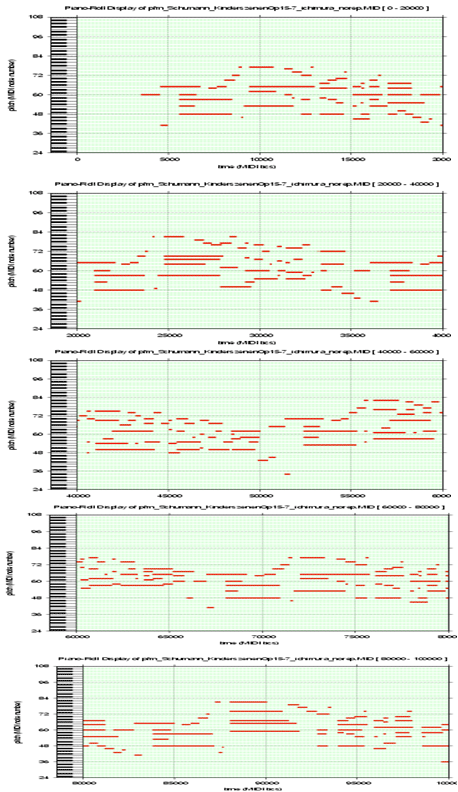
- 図4のピアノロールで示されるシューマン作曲「トロイメライ」の演奏(MIDIデータ)について自動採譜を行った結果が、図5の楽譜です。この演奏はテンポ変動が激しいにもかかわらず、精度良く楽譜が推定されていることが確認できます。このようにテンポが未知で変動する演奏からリズムを適切に推定することができることが確認できました。
- また誤りが図6のように多声部の処理や装飾音に確認できました。今後はこのような音について音楽構造解析による正確な記譜技術が課題といえます。
 |
 |
 |
| 図4. 「トロイメライ」演奏のピアノロール |
図5. 推定された楽譜 |
図6. 推定誤りの例 |
[ 研究室ホームページへ戻る ]