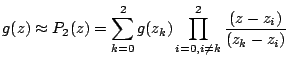The goal under consideration is to find the distribution (mean and variance) of noisy speech
parameter ![]() , given the distributions for noise parameters
, given the distributions for noise parameters ![]() and
and ![]() ,
and clean speech parameter
,
and clean speech parameter ![]() . First, mean, i.e. expectation value,
of
. First, mean, i.e. expectation value,
of ![]() is given as:
is given as:
Therefore, to find the value of
![]() , we first expand the
function
, we first expand the
function ![]() into a polynomial
that can closely approximate it within a given range, with its low order
as far as possible. The polynomial approximation can be simplified by
reducing function
into a polynomial
that can closely approximate it within a given range, with its low order
as far as possible. The polynomial approximation can be simplified by
reducing function ![]() to univariate one, by taking
to univariate one, by taking ![]() , where
, where
![]() .
.
In this work, 2nd-order Lagrange interpolating polynomial is
used to approximate the function ![]() , given as:
, given as:
The points ![]() ,
, ![]() and
and ![]() can be specified manually (one point
at
can be specified manually (one point
at ![]() and other two chosen to minimize error in the required range),
or instead, Chebyshev-Lagrange polynomial can be used that specifies the
points itself.
and other two chosen to minimize error in the required range),
or instead, Chebyshev-Lagrange polynomial can be used that specifies the
points itself.
Figure 2 shows different polynomials used to
approximate function
![]() when
when ![]() . In Figure
2a, the points selected for Lagrange polynomial
expansion are
. In Figure
2a, the points selected for Lagrange polynomial
expansion are ![]() ,
,
![]() and
and ![]() . As seen in the figure, Lagrange
polynomial has been able to approximate the
function up to larger range and more accurately than even 2-nd order
Taylor's series. When variance of
. As seen in the figure, Lagrange
polynomial has been able to approximate the
function up to larger range and more accurately than even 2-nd order
Taylor's series. When variance of ![]() is low, we can keep points
is low, we can keep points ![]() and
and ![]() closer to
closer to ![]() ; however, when
; however, when ![]() has large variance, the points
should be extended farther from
has large variance, the points
should be extended farther from ![]() . However, extending them too farther introduces inaccuracies in
the approximation in region close to
. However, extending them too farther introduces inaccuracies in
the approximation in region close to
![]() , where most of data
occurs. Therefore, the points
, where most of data
occurs. Therefore, the points ![]() and
and ![]() should be placed at some
optimum values depending on the variance of
should be placed at some
optimum values depending on the variance of ![]() .
.
Finally, Eq.(6) reduces to
![]() form, where
form, where ![]() ,
, ![]() and
and ![]() are constants. Therefore:
are constants. Therefore:
| (7) |
Using this estimated value of ![]() in Eq. 5, the mean for
corrupted speech vector can be computed. As, the accurate value of mean is more important than that of
variance, the covariance matrix can be retained as it is for
the clean speech. However, expression for adapting diagonal variances
can be derived from above approximation, in terms of higher-order
moments (up to 4th moment) of
in Eq. 5, the mean for
corrupted speech vector can be computed. As, the accurate value of mean is more important than that of
variance, the covariance matrix can be retained as it is for
the clean speech. However, expression for adapting diagonal variances
can be derived from above approximation, in terms of higher-order
moments (up to 4th moment) of ![]() , and diagonal variances can be adapted
as well.
, and diagonal variances can be adapted
as well.
The method for estimating model parameters for corrupted speech is shown in Figure
4. As approximation is done in log-spectral domain,
the HMM parameters of clean speech and noises in cepstral domain are
converted into log-spectral domain by taking inverse DCT. This
conversion of parameter vector
from cepstral to log-spectral domain requires knowledge of
![]() . In case if the given model parameters do not include
. In case if the given model parameters do not include ![]() , it
can be computed, as worked out in [12], by noticing the fact that the
sum
of the energies of Mel bands in linear spectral domain equals to
total frame energy.
, it
can be computed, as worked out in [12], by noticing the fact that the
sum
of the energies of Mel bands in linear spectral domain equals to
total frame energy.
The statistics to account for channel distortions can be obtained by using EM based approach by maximizing the likelihood score as described in [13]. Some adaptation data are required to estimate the statistics for channel distortion.
In all cases, only diagonal elements of covariance matrix of speech and noise HMMs are considered, in order to avoid the complexity and reduce the computational expense of the algorithm.
|
[width=.9]eps/mean6p1.eps
|